Kafka
Apache Kafka 是一个分布式流处理平台。
- Kafka 作为一个集群,运行在一台或者多台服务器上.
- Kafka 通过 Topic 对存储的流数据进行分类。
- 每条记录中包含一个 key,一个 value 和一个 timestamp(时间戳)。
概念
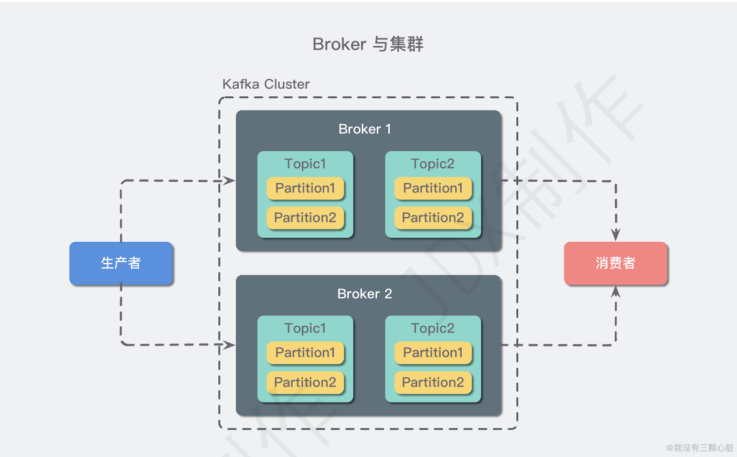
- Producer:生产者
- Consumer:消费者
- Topic:Kafka 中的消息以 Topic 为单位进行归类,生产者负责将消息发送到特定的 Topic(发送到 Kafka 集群中的每一条消息都要指定一个 Topic),而消费者负责订阅 Topic 并进行消费。
- Partition:Topic 是一个逻辑上的概念,它还可以细分为多个 Partition,一个 Partition 只属于单个 Topic。同一 Topic 下的不同 Partition 包含的消息是不同的,Partition 在存储层面可以看作一个可追加的日志文件(Log),消息在被追加到 Partition 日志文件的时候都会分配一个特定的偏移量(offset)。
- Broker: Kafka 中的一台或多台服务器统称 Broker。
- Zookeeper:Kafka 强依赖于 zookeeper ,每当一个 Broker 启动时,它会将自己注册到 zookeeper 的临时节点;Kafka 利用 zookeeper 临时节点来管理 Broker 生命周期。
- Cluster:若干个 Broker 组成一个集群(Cluster),其中集群内某个 Broker 会成为集群控制器(Cluster Controller),它负责管理集群,包括分配 Partition 到 Broker、监控 Broker 故障等。
- Leader:在集群内,一个 Partition 由一个 Broker 负责,这个 Broker 也称为这个 Partition 的 Leader。
数据存储
Message
Partition 中的每条 Message 包含了以下三个属性:offset,MessageSize,data。
- offset:是 Message 在 Partition 中的唯一标识,可以认为 offset 是 Partition 中 Message 的 id,Kafka 通过它来保证消息在 Partition 内的顺序性,不过 offset 并不跨越 Partition,Kafka 保证的是 Partition 有序而不是 Topic 有序。
- MessageSize:表示消息内容 data 的大小。
- data:Message 的具体内容。
Segment
Partition 物理上由多个 segment 文件组成,每个 segment 大小相等,顺序读写,符合分布式系统 Partition 分桶的设计思想。每个 segment 数据文件以该段中最小的 offset 命名,文件扩展名为 .log。这样在查找指定 offset 的 Message 的时候,用二分查找就可以定位到该 Message 在哪个 segment 数据文件中。
Kafka 的 message 是按 Topic 分类存储的,Topic 中的数据又是按照一个一个的 Partition 即 Partition 存储到不同 Broker 节点。每个 Partition 对应了操作系统上的一个文件夹,Partition 实际上又是按照 segment 分段存储的。符合分布式系统 Partition 分桶的设计思想。
文件系统
Kafka 的消息是存在于文件系统之上的,其高度依赖文件系统来存储和缓存消息。每一个 Partition 最终对应一个目录,里面存储所有的消息和索引文件。默认情况下,每一个 Topic 在创建时如果不指定 Partition 数量时只会创建 1 个 Partition。命名规则是:<Topic_name>-<Partition_id> 。
任何发布到 Partition 的消息都会被追加到 Partition 文件的尾部,这样的顺序写磁盘操作让 Kafka 的效率非常高。每一条被发送到 Broker 的消息,会根据规则被存储到具体的 Partition 中。如果规则设置的合理,所有消息可以均匀分布到不同的 Partition 中。
Kafka 为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为 .index。index 文件中并没有为数据文件中的每条 Message 建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
Producer
负载均衡
由于 Topic 由多个 Partition 组成,且 Partition 会均衡分布到不同 Broker 上,因此,为了有效利用 Broker 集群的性能,提高消息的吞吐量,Producer 可以通过随机或者 hash 等方式,将消息平均发送到多个 Partition 上,以实现负载均衡。
批量发送
批量发送是提高消息吞吐量重要的方式,Producer 端可以在内存中合并多条消息后,以一次请求的方式发送了批量的消息给 Broker,从而大大减少 Broker 存储消息的 IO 操作次数。但也一定程度上影响了消息的实时性。
1 | 相当于以时延为代价,换取更好的吞吐量。 |
批量压缩
Producer 端可以通过 GZIP 或 Snappy 格式对消息集合进行压缩。Producer 端进行压缩之后,在 Consumer 端需进行解压。压缩的好处就是减少传输的数据量,减轻对网络传输的压力。
如果每个消息都压缩,那么压缩率就会相对很低,所以 Kafka 使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩。
1 | 在对大数据处理上,瓶颈往往体现在网络上而不是 CPU(压缩和解压会耗掉部分 CPU 资源)。 |
Consumer
Consumer Group
同一 Consumer Group 中的多个 Consumer 实例,同时消费同一个 Topic 中的不同 Partition,以实现并行消费。
当 Consumer 数量大于 Topic 数量时,多余的 Consumer 将会空闲。
高可用
- Topic 的每个 Partition 存在于不同的 Broker 上,Topic 的数据,是分散放在多个机器上的,每个机器存放一部分数据。Kafka 0.8 以后,提供 Replica 副本机制:每个 Partition 的数据都会同步到其它机器上,形成自己的多个 Replica 副本;所有 Replica 会选举一个 Leader,其他 Replica 就是 Follower。
- 生产和消费均只与 Leader 产生联系:
- 写的时候,Producer 就写入 Leader,然后 Leader 将数据落地写本地磁盘,接着其他 Follower 自己主动从 Leader 来 Pull 数据。一旦所有 Follower 同步好数据,就会发送
ack给 Leader,Leader 收到所有 Follower 的 ack 之后,就会返回写成功的消息给 Producer。 - 读的时候,Consumer 只会从 Leader 中读,但是只有当一个 Message 已经被所有 Follower 都同步成功并返回
ack的时候,这个消息才会被 Consumer 读到。
- 写的时候,Producer 就写入 Leader,然后 Leader 将数据落地写本地磁盘,接着其他 Follower 自己主动从 Leader 来 Pull 数据。一旦所有 Follower 同步好数据,就会发送
- Kafka 会均匀地将一个 Partition 的所有 Replica 分布在不同的机器上,提高容错性。如果某个 Broker 宕机了,该 Broker 上面的 Partition 在其他机器上都有副本。如果这个宕机的 Broker 上面有某个 Partition 的 Leader,此时会从 Follower 中重新选举一个新的 Leader 出来,继续读写新的 Leader 即可。
可靠性传输
Consumer 端
- 唯一可能导致消费者弄丢数据的情况——消费者自动提交 offset,但消费端因为某些原因未能消费数据。因此可以关闭自动提交 offset,在处理完之后消费者手动提交 offset,就可以保证数据不会丢。但此时可能会有重复消费,需要消费端自行保证幂等性。
Kafka 端
- Kafka 某个 Broker 宕机,然后重新选举 Partition 的 Leader。如果此时其他的 Follower 刚好还有些数据没有同步,导致部分数据丢失。
- 给 Topic 设置参数副本数量
Replication.factor:这个值必须大于 1,要求每个 Partition 必须有至少 2 个副本。 - 在 Kafka 服务端设置参数最小同步副本数
min.insync.Replicas:这个值必须大于 1,要求一个 Leader 至少感知到有至少一个 Follower 还跟自己保持联系。 - 在 Producer 端设置
acks=all:这个是要求每条数据,必须是写入所有 Replica 之后,才能认为是写成功了。 - 在 Producer 端设置
retries=MAX (较大值):要求一旦写入失败,就无限重试。
Producer 端
- 设置
acks=all,一定不会丢。 - 你的 Leader 接收到消息,所有的 Follower 都同步到消息之后,才认为本次写成功;如果没满足这个条件,生产者会自动不断重试。
数据丢失
- 如果 auto.commit.enable=true,当 consumer fetch 了一些数据但还没有完全处理掉的时候,刚好到 commit interval 出发了提交 offset 操作,接着 consumer crash 掉了。这时已经 fetch 的数据还没有处理完成但已经被 commit 掉,因此没有机会再次被处理,数据丢失。
- 网络负载很高或者磁盘很忙写入失败的情况下,没有自动重试重发消息。
- 如果磁盘坏了,会丢失已经落盘的数据
- 单批数据的长度超过限制会丢失数据,报 kafka.common.MessageSizeTooLargeException 异常
- Partition Leader 在未完成副本数 follows 的备份时就宕机的情况,即使选举出了新的 Leader 但是已经 push 的数据因为未备份就丢失了
- kafka 的数据一开始就是存储在 PageCache 上的,定期 flush 到磁盘上的,也就是说,不是每个消息都被存储在磁盘了,如果出现断电或者机器故障等,PageCache 上的数据就丢失了。
- 由于 Kafka consumer 默认是自动提交位移的,所以如果在消息处理完成前就提交了 offset,那么就有可能造成数据的丢失。
Producer 端
- Replication.factor,副本的数量,至少大于 1;
- min.insync.Replications,必须大于 1,要求每个 Leader 至少感知到有一个 Follower 和自己保持同步;
- ack = all,确保每个数据必须是写入了所有副本之后,才算写成功;
- retries,需要重新发送次数;
- log.flush.interval.messages、log.flush.interval.ms,配置 flush 间隔。
Broker 端
Topic 设置多 Partition,Partition 自适应所在机器,为了让各 Partition 均匀分布在所在的 Broker 中,Partition 数要大于 Broker 数。
Partition 是 kafka 进行并行读写的单位,是提升 kafka 速度的关键。
- Broker 能接收消息的最大字节数的设置一定要比消费端能消费的最大字节数要小,否则 Broker 就会因为消费端无法使用这个消息而挂起。
- Broker 可赋值的消息的最大字节数设置一定要比能接受的最大字节数大,否则 Broker 就会因为数据量的问题无法复制副本,导致数据丢失。
Consumer 端
- enable.auto.commit=false ,关闭自动提交位移,并在消息被完整处理之后再手动提交位移。
低延迟高吞吐
顺序读写
Kafka 将消息记录持久化到本地磁盘中,实际上不管是内存还是磁盘,快或慢关键在于寻址的方式,基于磁盘的随机读写确实很慢,但磁盘的顺序读写性能却很高。
Kafka 的 message 是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得 Kafka 写入吞吐量得到了显著提升 。每一个 Partition 其实都是一个文件 ,收到消息后 Kafka 会把数据插入到文件末尾。
同样这种方法不能删除数据 ,所以 Kafka 是不会删除数据的,它会把所有的数据都保留下来,每个消费者 Consumer 对每个 Topic 都有一个 offset 用来表示读取到了第几条数据 。
如果不删除硬盘肯定会被撑满,所以 Kakfa 提供了两种策略来删除数据,一是基于时间,二是基于 Partition 文件大小。
Page Cache
为了优化读写性能,Kafka 利用了操作系统本身的 Page Cache,即利用操作系统自身的内存而不是 JVM 空间内存。这样做的好处有:
- 避免 Object 消耗:如果是使用 Java 堆,Java 对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
- 避免 GC 问题:随着 JVM 中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在 GC 问题。
相比于使用 JVM 或 in-memory cache 等数据结构,利用操作系统的 Page Cache 更加简单可靠。首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。其次,操作系统本身也对于 Page Cache 做了大量优化,提供了 write-behind、read-ahead 以及 flush 等多种机制。再者,即使服务进程重启,系统缓存依然不会消失,避免了 in-process cache 重建缓存的过程。
零拷贝技术
当 Kafka 客户端从服务器读取数据时,如果不使用零拷贝技术,那么大致需要经历这样的一个过程:
- 操作系统将数据从磁盘上读入到内核空间的读缓冲区中。
- 应用程序(也就是 Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中。
- 应用程序将数据从用户空间的缓冲区再写回到内核空间的 socket 缓冲区中。
- 操作系统将 socket 缓冲区中的数据拷贝到 NIC 缓冲区中,然后通过网络发送给客户端。
Kafka 使用零拷贝技术,即直接将数据从内核空间的读缓冲区直接拷贝到内核空间的 socket 缓冲区,然后再写入到 NIC 缓冲区,避免了在内核空间和用户空间之间穿梭。
1 | 零拷贝并非指一次拷贝都没有,而是避免了在内核空间和用户空间(的读缓冲区)之间的拷贝。 |
蓄水池机制
生产的流程主要就是一个 Producer 线程和一个 sender 线程,它们之间通过 BatchQueue 来获取数据,它们的关系是一一对应的,所以 kafka 的生产过程都是异步过程,它的同步和异步指的是接收响应结果的模式是同步阻塞还是异步回调。
同步接收是依据 send 之后返回 Future,再调用 Future 的 get 方法进行阻塞等待。下面我们就从 Producer 和 sender 两个类所对应的流程来进行分析,他们分别是消息收集过程和消息发送过程。消息的收集过程的数据最终是放在 BatchQueue,像是将水流入了一个蓄水池的场景。
参考文献
- https://blog.csdn.net/qq_34319644/article/details/96586147
- https://doocs.github.io/advanced-java/#/docs/high-concurrency/why-mq
- https://doocs.github.io/advanced-java/#/docs/high-concurrency/how-to-ensure-high-availability-of-message-queues
- https://doocs.github.io/advanced-java/#/docs/high-concurrency/how-to-ensure-the-reliable-transmission-of-messages
- https://cloud.tencent.com/developer/article/1787280