Hadoop-HDFS
特点
- 不支持并发写入
- 不支持文件当随机修改,仅支持数据追加(append)
架构
NameNode
- 守护进程,负责维护整个文件系统,存储着整个文件系统的元数据信息,管理命名空间
- 配置副本策略(?
- 管理数据块(block)映射信息
- 处理读写请求
- 其中镜像备份
Fsimage和 日志备份Edit.log的内容 Namenode 不会持久化存储,而是在启动时重建这些数据
DataNode
- 具体工作节点,存储实际的数据块
- 执行数据块的读写操作
SecondaryNameNode
- 主要负责定期合并
Fsimage和Edit.log,并推送给 NameNode - 在紧急情况下,可辅助恢复 NameNode
Client
- 文件切分
- 节点交互
局限性
Namespace 限制:由于 NameNode 在内存中存储所有的元数据,因此单个 NameNode 所能存储的对象(文件+块)数目受到 NameNode 所在 JVM 的 heap size 的限制。
隔离问题:由于仅有一个 NameNode,无法隔离各个程序,因此 HDFS 上的一个实验程序就很有可能影响整个 HDFS 上运行的程序。
性能问题:由于仅有一个 NameNode,整个 HDFS 的吞吐量受限于单个 NameNode 的吞吐量。
Block
- 物理上分块存储
dfs.blocksize= 64M- 最佳配置:寻址时间为传输时间的 1%;块的设置取决于磁盘传输速率
- 块设置过小,会增加寻址时间;块设置过大,传输时间过久
写流程
- Client 与 NameNode 建立连接,创建文件元数据信息
- NameNode 判断元数据是否有效
- NameNode 触发副本存放策略,返回一个有序的 DataNode 列表
- Client 与 DataNode 建立管道连接,Client 将文件块切成一个个 Packet
- Client 将 Packet 放入管道并向第一个 DataNode 传输
- 第一个 DataNode 保存后发送给第二个 DataNode,第二个 DataNode 保存后以此类推
- 几个 DataNode 会与 NameNode 建立心跳,确认传输完成后完成写流程
副本节点选择
- 若 Client 在集群内,则第一个副本在其所处节点上, 否则随机选择一个节点
- 第二个副本选择与第一个所处相同机架的随机节点
- 第三个副本选择不同机架的随机节点
读流程
- Client 通过 ==Distribution File System==与 NameNode 交互
- NamdNode 通过查询元数据信息,获取文件块的位置,NameNode 会按照距离策略排序返回 DataNode 列表
- Client 从最近的 DataNode 开始读,先建立管道,然后 DataNode 以 Packet 为单位将数据传给 Client
元数据管理
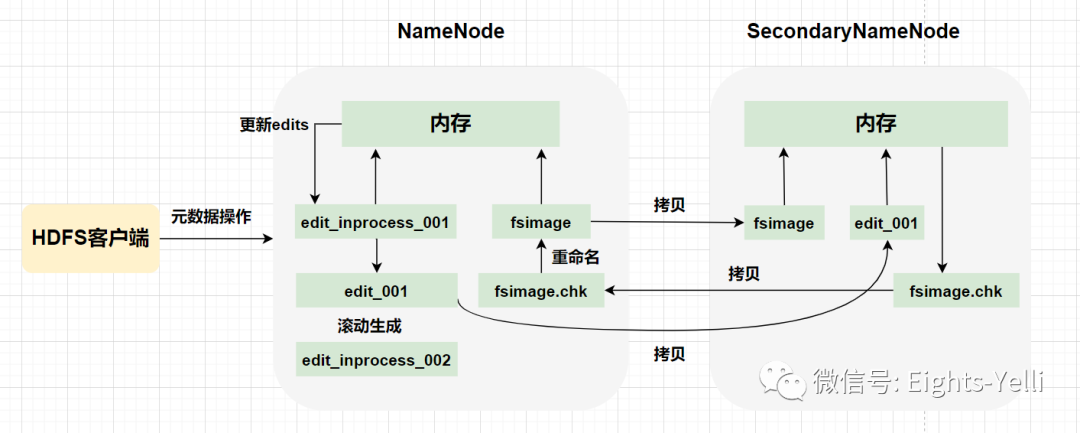
采用内存 + 磁盘的方式进行元数据的管理:内存-> NameNode,磁盘->Fsimage & Edits。
- Fsimage:NameNode 中对元数据进行持久化存储生成的序列化文件,保存了最新的元数据检查点包含所有目录和文件索引。
- Edits:记录Client 更新元数据信息的每一步操作,只进行追加操作,以日志的形式记录,保存自最新检查点后的命名空间的变化。
工作机制
NameNode 启动时,先滚动 Edits 并生成一个空的 edits.inprogress,然后加载 Edits 和 Fsimage 到内存中,此时 NameNode 内存就持有最新的元数据信息。
Client 开始对 NameNode 发送元数据的增删改的请求,这些请求的操作首先会被记录到 edits.inprogress 中,如果此时 NameNode 挂掉,重启后会从 Edits 中读取元数据的信息。然后,NameNode 会根据 Edits 按步执行。
由于 Edits 中记录的操作会越来越多,Edits 文件会越来越大,导致 NameNode 在启动加载 Edits 时会很慢,所以需要定期对 Edits 和 Fsimage 进行合并:将Edits 和 Fsimage 加载到内存中 , 按照 Edits 按步执行 , 最终形成新的 Fsimage。
流程
- 启动 NameNode,创建/直接加载 Fsimage 和 Edits
- Client 对元数据进行增删改请求
- NameNode 记录操作日志,更新 Edits
- NameNode 在内存中对数据进行增删改
- SecondaryNameNode 询问 NameNode 是否需要 CheckPoint(触发 CheckPoint 需要满足两个条件中的任意一个,定时时间 1 h 到或 Edits 中数据已写满 64 M),并直接带回 NameNode 结果
- SecondaryNameNode 请求执行 CheckPoint
- NameNode 滚动 Edits 并生成一个空的 edits.inprogress(滚动 Edits 的目的是给 Edits 打个标记,以后所有新的操作都写入 edits.inprogress),其他未合并的 Edits 和 Fsimag 会拷贝到 SecondaryNameNode
- SecondaryNameNode 加载 Edits 和 Fsimage 加载到内存中进行合并,生成
fsimage.chkpoint - 拷贝 fsimage.chkpoint 到 NameNode
- NameNode 将 fsimage.chkpoint 重新命名成 Fsimage
集群安全模式
集群处于安全模式,不能执行重要操作(写操作)。
集群启动完成后,自动退出安全模式。
在启动一个刚刚格式化的 HDFS 集群时,因为系统中还没有任何块,所以 NameNode 不会进入安全模式。
流程
- NameNode 启动:首先将 Fsimage 载入内存,并执行 Edits 中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的 Fsimage 和一个空的 Edits。此时,NameNode 开始监听 DataNode 请求。这个过程期间,NameNode 一直运行在安全模式,即 NameNode 的文件系统对于 Client 来说是只读的。
- DataNode 启动:在安全模式下,各个 DataNode 会向 NameNode 发送最新的块列表信息。
- 安全模式退出:判断如果满足“最小副本条件”,NameNode 会在30秒钟之后就退出安全模式。最小副本条件指的是在整个文件系统中 99.9% 的块满足最小副本级别(默认值:``dfs.replication.min` = 1)。
数据存储
工作机制
- 一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据,包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode 启动后向 NameNode 注册,通过后,周期性(1 小时)地向 NameNode 上报所有的块信息。
- 心跳每 3 秒一次,返回结果带有 NameNode 给该 DataNode 的命令。如果超过 10 分钟没有收到 DataNode 的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
数据完整性
- (周期性)验证
checkSum
掉线时限
参数设置
- Timeout = 2 *
dfs.namenode.hearteat.recheck-interval+ 10 *dfs.hearteat.interval - dfs.namenode.hearteat.recheck-interval = 300000 ms
- dfs.hearteat.interval = 3 s
高可用
- 通过双 NameNode 消除单点故障
工作要点
- NameNode 各自存储一份元数据
- Edits 日志只有 Active 状态的 NameNode 节点可以做写操作,两个 NameNode 都可以读取 Edits
- 共享的 Edits 放在一个共享存储中管理
- 需要一个状态管理功能模块,防止
brain split的发生
自动故障转移工作机制
- 故障检测:集群中的每个 NameNode 在 ZooKeeper 中维护了一个持久会话,如果机器崩溃,ZooKeeper 中的会话将终止,ZooKeeper 会通知另一个 NameNode 需要触发故障转移。
- 现役 NameNode 选择:ZooKeeper 提供了一个简单的机制用于选择唯一的一个节点为 active 状态。如果现役 NameNode 崩溃,另一个节点可能从 ZooKeeper 获得特殊的排外锁以表明它应该成为现役 NameNode。
ZooKeeper
ZKFC 是自动故障转移中的另一个新组件,是 ZooKeeper 的客户端,也监视和管理 NameNode 的状态。每个运行 NameNode 的主机也运行了一个 ZKFC 进程。
- 健康监测:ZKFC 使用一个健康检查命令定期地 ping 与之在相同主机的 NameNode, 只要该 NameNode 及时地回复健康状态,ZKFC 认为该节点是健康的。如果该节点崩溃、冻结或进入不健康状态,将标识该节点为非健康的。
- 会话管理:当本地 NameNode 是健康的,ZKFC 保持一个在 ZooKeeper 中打开的会话。如果本地 NameNode 处于 active 状态,ZKFC 也保持一个特殊的 znode 锁, 该锁使用了 ZooKeeper 对短暂节点的支持,如果会话终止,锁节点将自动删除。
- 基于 ZooKeeper 的 NameNode 选择:如果本地 NameNode 是健康的,且 ZKFC 发现没有其它的节点当前持有 znode 锁,它将为自己获取该锁。如果成功,则它将使本地的 NameNode 的状态为 Active 并负责运行故障转移进程。
假死
同时出现两个 Active 状态的 NameNode,出现脑裂现象
kill指令- 用户自定义脚本程序